Core GPU Engine
>_ Module 01 — C++17 / CUDA BackendThe engine under SigTekX: a C++17 / CUDA17 pipeline that turns a raw PCM stream into a magnitude spectrum in under two hundred microseconds. Two executors — one built for maximum throughput, one built for continuous streaming — share the same kernels but take opposite paths through memory. This page walks the architecture layer by layer: from the pybind11 surface down through the ring buffer, the three-stream pipeline, the cuFFT plans, and the RAII wrappers that keep it all leak-free.
Architecture at a Glance
The C++ side is split into eight focused layers. Public headers stay CUDA-free so the Python build can include them without pulling in the toolkit. Everything CUDA-specific lives in implementation files behind the Pimpl boundary.
Dual Executors
Two executors, one pipeline. BatchExecutor takes fixed-size input and copies it straight into device memory for maximum throughput. StreamingExecutor accepts arbitrary chunks, accumulates them in per-channel ring buffers, and drains frames as soon as they're available. The gap between them — about 40% on latency — is the architectural cost of real-time flexibility, not a bug.
- Single memcpy — host buffer straight into d_input
- Round-robin device buffers for H2D/compute overlap
- One submit() call equals exactly one batch
- Zero ring-buffer overhead on the CPU side
- Use for offline analysis and benchmarking
- Per-channel pinned ring buffers (3 × NFFT capacity)
- Zero-copy peek_frame() — DMA direct from pinned memory
- Drains all ready frames per submit() — no overflow on warmup
- Optional background consumer thread (lock-free SPSC)
- Use for sensor integration and real-time monitoring
Processing Pipelines
Both executors use the same three-stage kernel pipeline (Window → FFT → Magnitude)
and the same three CUDA streams (H2D, Compute, D2H). What differs is how input
samples arrive at d_input. BatchExecutor copies once. StreamingExecutor
pushes into a ring buffer first, then DMAs directly from it.


Memory Model
The memory footprint mirrors the behavioral split. Batch mode has no streaming accumulator — just double-buffered device memory sized for one fixed batch. Streaming mode adds per-channel pinned ring buffers that hold three frames' worth of samples at all times, enough to survive long warmup runs without overflowing.


Engineering Highlights
peek_frame() API returns a span pointing directly into that
memory — no staging hop. cudaMemcpyAsync DMAs straight from the
ring buffer. Wraparound frames issue two spans; advance() runs
only after the D2H sync so pointers stay valid during transfer.
H2D, Compute, D2H —
with event-based dependencies. Frame N+1's H2D overlaps frame N's compute,
which overlaps frame N−1's D2H. Round-robin device buffers let the pipeline
run two or three frames deep without ever allocating on the hot path.
cudaStream_t,
cufftHandle, and the rest behind a unique_ptr<Impl>.
CUDA resources are RAII-wrapped (CudaStream, CufftPlan,
DeviceBuffer, PinnedHostBuffer), move-only, and
self-destructing — no manual cleanup, no leaks on exception paths.
WindowStage, FFTStage,
MagnitudeStage) implements a minimal
ProcessingStage interface. StageFactory composes
pipelines from configuration at runtime, so adding a new stage — bandpass,
PSD, log-magnitude — is a single class implementation plus one factory entry.
Measured Performance
End-to-end benchmarks from the Python layer — same pipeline, measured across the pybind11 boundary with locked GPU clocks for low-variance numbers. The C++ engine in isolation runs faster still; the ~61 µs gap is the full cost of zero-copy NumPy handoff.
>_ C++ backend isolated: 109.6 µs mean / 287.7 µs p99 — pybind11 overhead ≈ 61 µs / frame
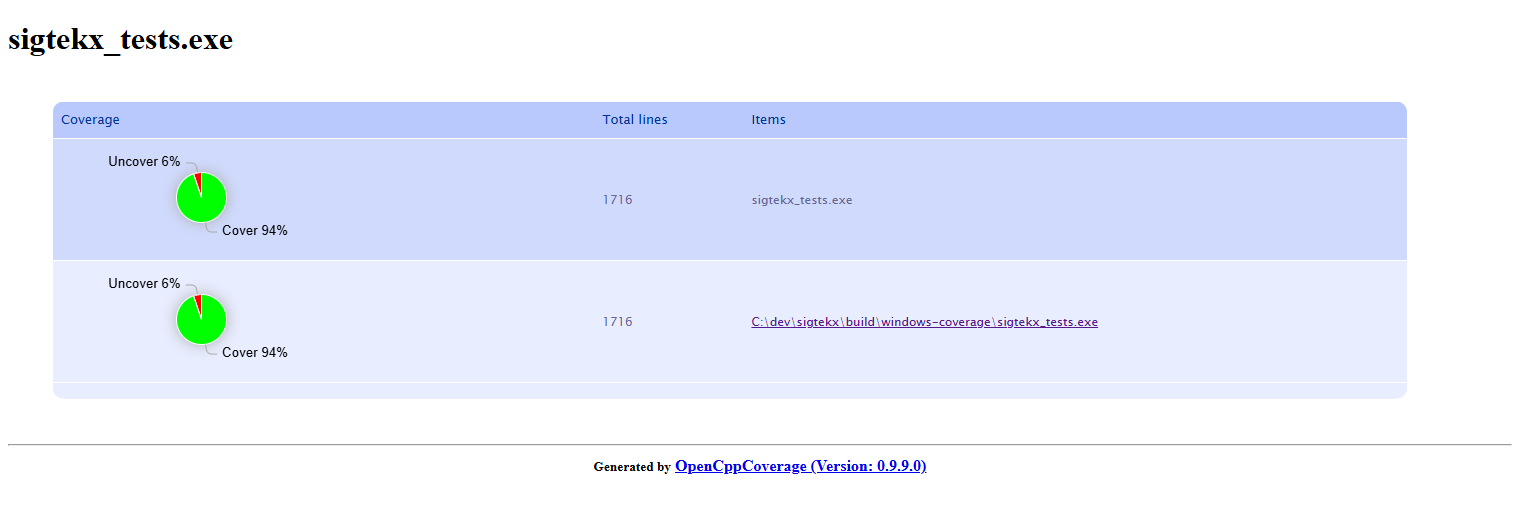
Test Coverage
The C++ test suite uses Google Test with gcovr reports. Headline coverage is strong
across the hot path — executors, kernels, ring buffer, pipeline. The uncovered
portions concentrate in files that are intentionally not unit-tested at the C++
layer: signal_utils.cpp (test signal generation, validated against
reference implementations), window_functions.hpp (pre-computed window
coefficients cross-checked against NumPy/SciPy), and executor_config.hpp
(a plain POD configuration struct).

Component Architecture
The full class and dependency map for the C++ side — every namespace, every public type, every processing stage. The diagram is dense by design; click to open it in the explorer for full-size panning and zooming.
