Cloud Infrastructure
>_ Module 02 — AWS GPU Benchmarking PipelineTaking the SigTekX engine from a local workstation to reproducible cloud benchmarks. A containerized deployment pipeline built on AWS EC2 spot GPU instances, with automated result collection to S3, real-time log streaming to CloudWatch, and Streamlit-based performance analysis — all for under $0.20 per run.
Architecture Overview
The cloud pipeline follows a simple loop: build locally, push to ECR, pull and run on a spot GPU instance, then download results. Every component is scoped, automated, and teardown-safe — no resources linger after the run.

AWS Services
Instance Configuration
>_ EC2 Benchmark Instance
Spot InstanceContainer Build
A two-stage Docker build separates compilation from runtime. The builder stage compiles
the C++/CUDA engine and packages it into a Python wheel. The production stage installs
only the wheel and runtime dependencies — no compilers, no source code, no build artifacts.
A non-root appuser runs inside the container for security.
- Install build tools + Miniconda
- Create Conda env from environment.build.yml
- CMake build of C++/CUDA engine
- Copy benchmarks + experiment configs
- pip wheel — produces .whl artifact
- Miniconda + runtime Conda env only
- Install .whl from builder stage
- Copy benchmark scripts + configs
- Non-root appuser for execution
- Entrypoint: conda run -n sigtekx
Deployment Pipeline
Four shell scripts handle the full lifecycle — from creating AWS resources to tearing them down. Each step is idempotent and safe to re-run.
latest and the current git commit SHA for traceability.
--gpus all and the awslogs driver, then uploads result CSVs to S3.
Supports --smoke, --full, and custom Hydra argument modes.
Observability
Container stdout/stderr streams directly to CloudWatch via Docker's built-in awslogs driver — no sidecar, no agent, no extra process. Locally, the same benchmark output is visible in WSL2 terminal and analyzed in the Streamlit dashboard after downloading results from S3.
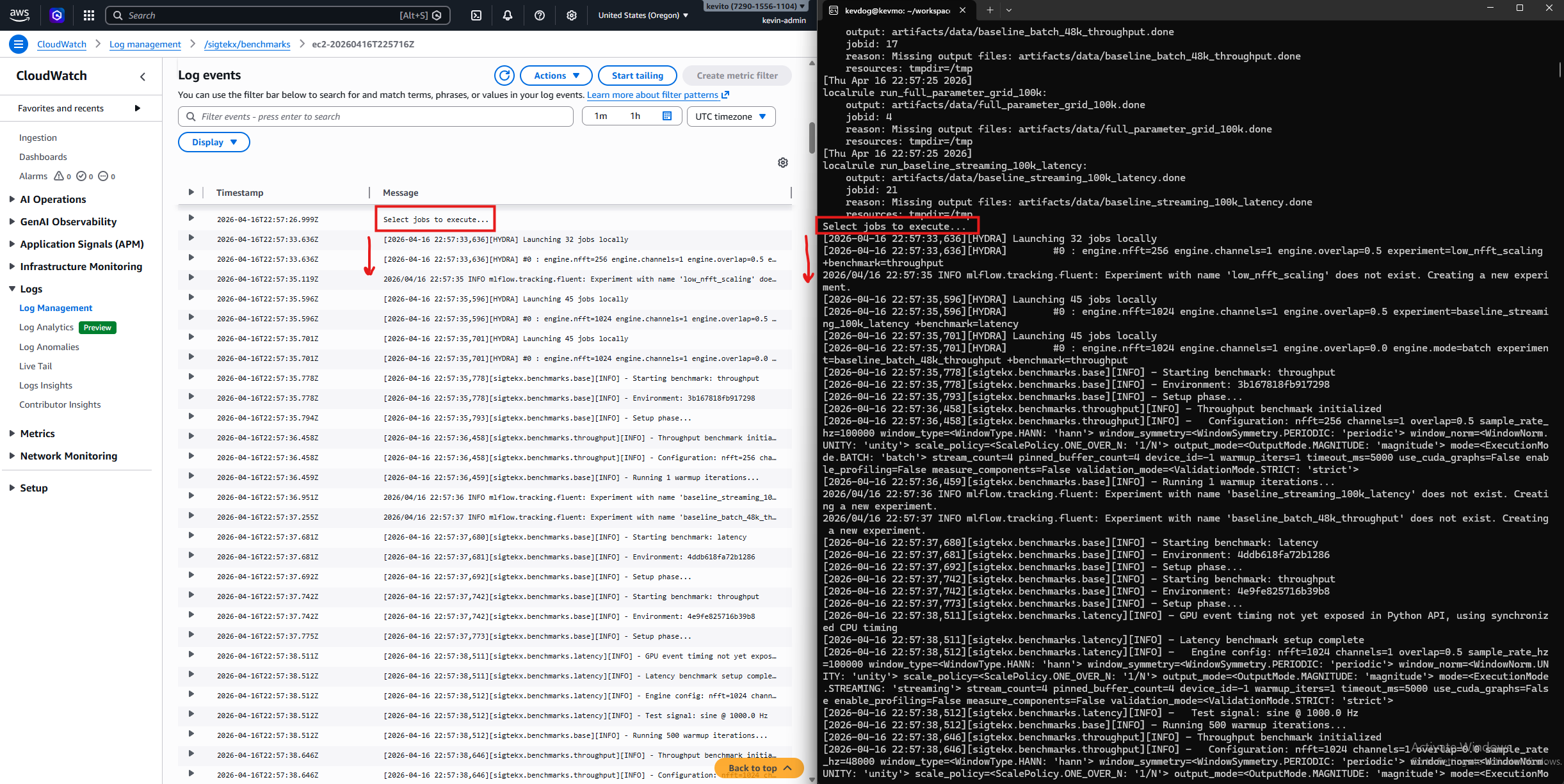
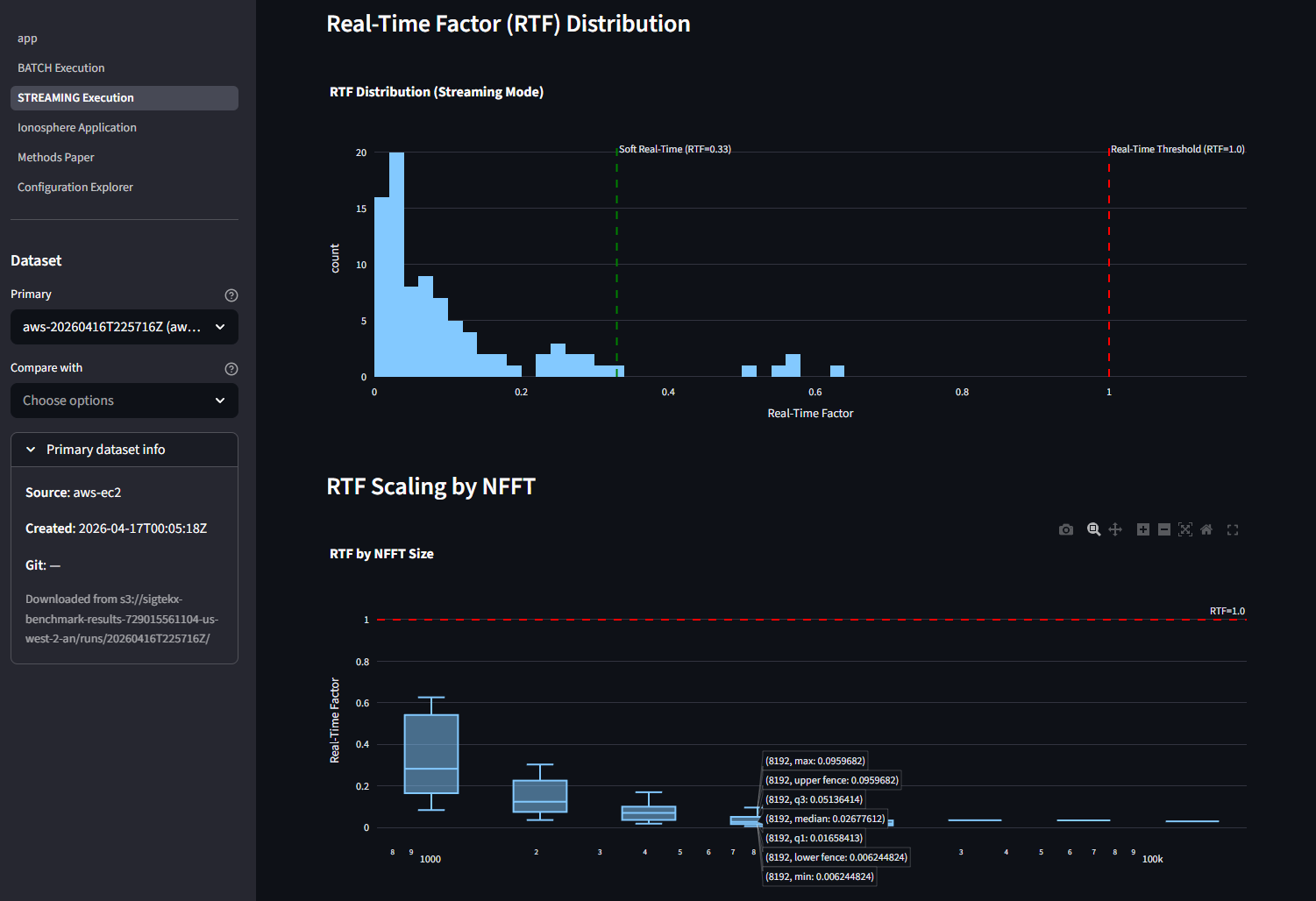
Cloud Performance
End-to-end benchmarks measured from inside the g4dn.xlarge container. The T4's Turing
architecture (sm_75) trades raw Ampere throughput for ~30% the hourly cost —
still clearing 100 kHz real-time with a 77x margin and even higher
spectral SNR than the local RTX 3090 Ti.
>_ Local RTX 3090 Ti reference: 171.1 µs mean / 305.5 µs p99 — Ampere is ~4.4x faster per frame
Design Decisions
Security
Scoped IAM Policy
Inline policy locked to one S3 bucket and one CloudWatch log group — no wildcard resource ARNs.
EC2-Only Trust
Trust policy restricted to ec2.amazonaws.com — role cannot be assumed by any other service.
Non-Root Container
appuser runs inside the container. No root access to the runtime environment.
Zero Credentials in Code
No secrets in env vars, Dockerfiles, or source. All auth flows through the instance role.
Cost Model
A full benchmark run takes approximately 30 minutes on g4dn.xlarge. A CloudWatch billing alarm backed by SNS email notifications ensures a forgotten spot instance can't silently burn through the budget.
| Component | Rate | Cost / Run |
|---|---|---|
| EC2 g4dn.xlarge spot | ~$0.16/hr | ~$0.08 |
| S3 storage (1 GB, 1 month) | $0.023/GB-mo | ~$0.02 |
| CloudWatch Logs ingest | $0.50/GB | <$0.05 |
| S3 requests + ECR | Negligible | <$0.01 |
| Total per run | ~$0.12 – $0.20 |
Detailed Architecture
The full architectural diagram maps every data flow — from the local Docker build through ECR, EC2, S3, CloudWatch, and back to the local Streamlit dashboard.
